今年春节,这些大模型厂商属于是一点寂寞也耐不住了。
轮流发射,啊不,应该说是轮流在喷射新的模型出来。
除了万众瞩目的 DeepSeek 还在憋气,其他大模型公司都没少闲着。。。
字节前几天搞了个 Seedance 2.0,靠着逼真的视频效果先下一城。
而智谱则是在海外整了个新活:
经常关注大模型发布的差友们这几天应该有刷到,前几天,程序员非常爱用的 AI 聚合平台,Openrouter 那边上架了一款匿名模型 —— Pony Alpha。

结果大家一上手使用后发现哥们是真能干事啊,定叫它好评如潮。


于是,热情吃瓜的海外网友就开始了经典的模型猜猜猜游戏,开始推测这个匿名模型是哪一家的手笔。
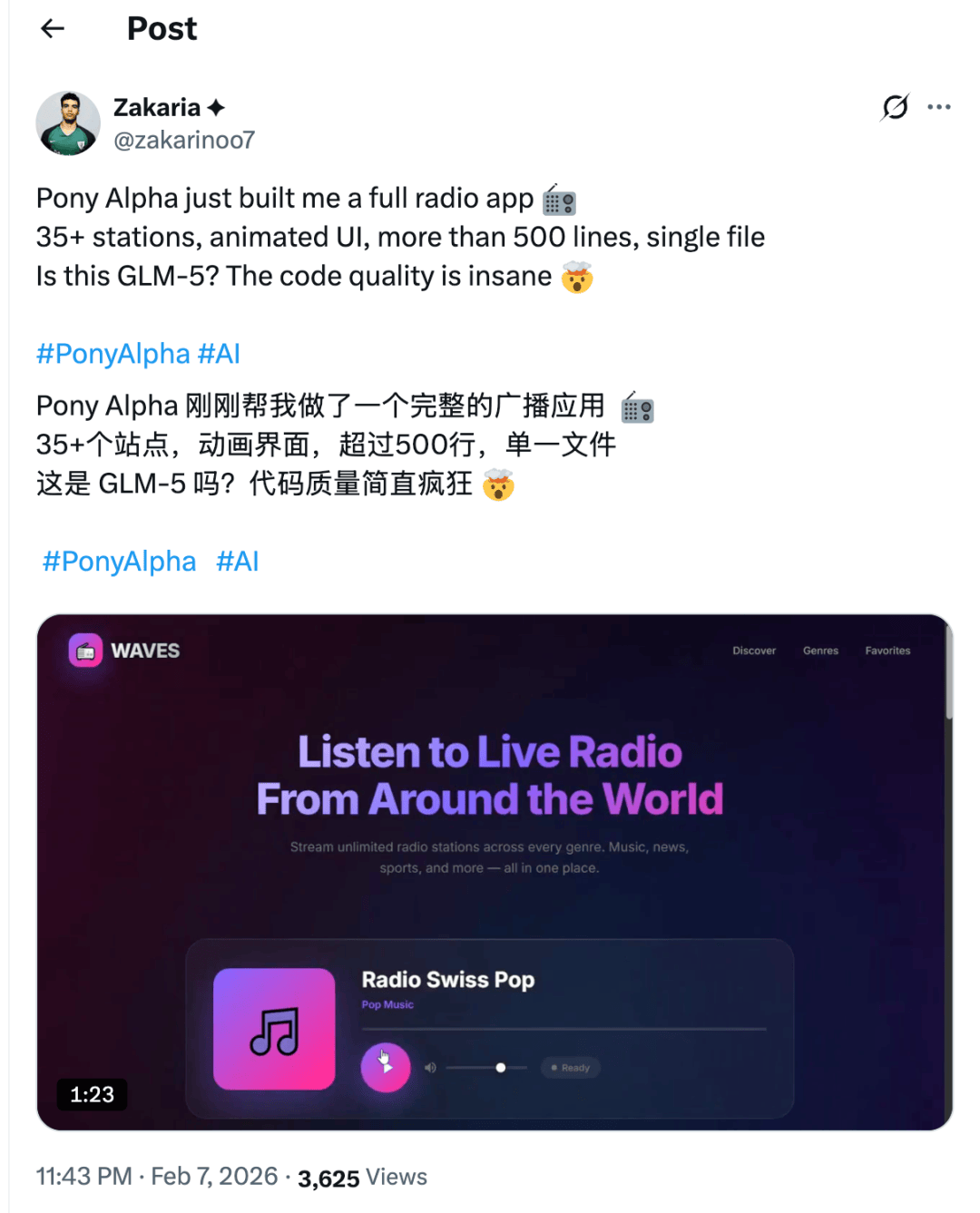
有说是 DeepSeek V4 的,也有说是 Grok 4.2 的,还有说是 llama 5 的。
还有人因为 Pony 这个代号,直接开始猜它是腾讯的新模型的。。。
可以说是众说纷纭。
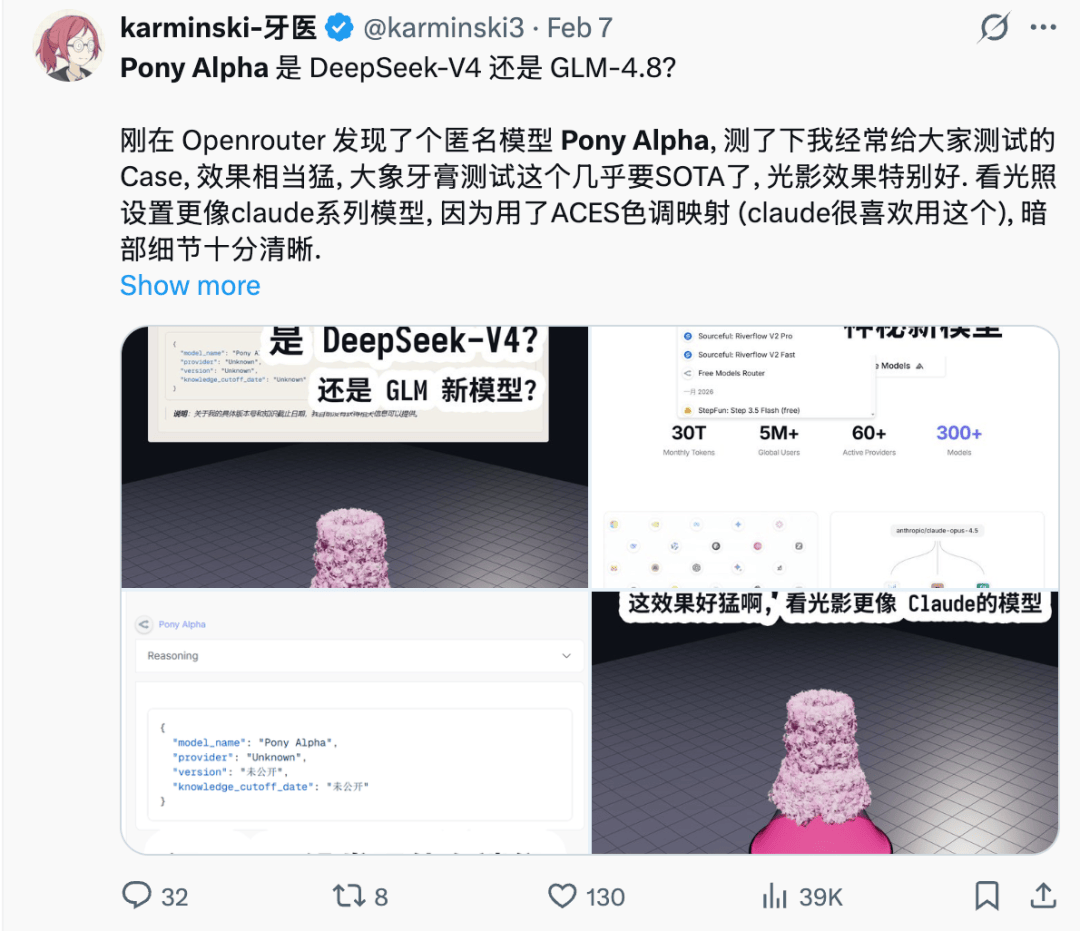
而昨天,谜底正式揭晓了。
不装了,我摊牌了。
这个化名为 pony 的新东西,正是来自于智谱的GLM-5,而且还是个开源的模型。

世超打开 GLM-5 的基准测试成绩翻了一下,在智谱最看中的代码能力这块,GLM-5 直接逼近了大家公认的 AI 编码冠军,Claude Opus 4.5。

当然,现在各种各样的 AI 排行榜太多了,大家可能不太理解智谱这次测的这个 CC-bench-V2 又是个啥排行榜,代表了啥?
我简单看了一下,智谱这次测的这个 CC-bench-V2,主要考验的是你模型补全代码的能力有多强。
说人话一点,就是把模型丢到一个没写完的工程里,然后看它能不能自个儿哼哧哼哧把项目给做完。
这块考的分越高,说明这次 GLM-5 处理复杂任务的能力越强。
众所周知,现在大家想让 AI 干的活那是越来越复杂,生成几个简单的 Html 文件已经难不倒这些 AI 大模型了。
而想要把大项目给做好,那就需要让模型具备这种处理复杂任务的能力。
另外还有个有趣的测试结果是,GLM-5 发生幻觉概率非常低。
当一个问题它不知道的时候,GLM-5 会有很大的概率直接说不知道,而不是原地开始胡编乱造。
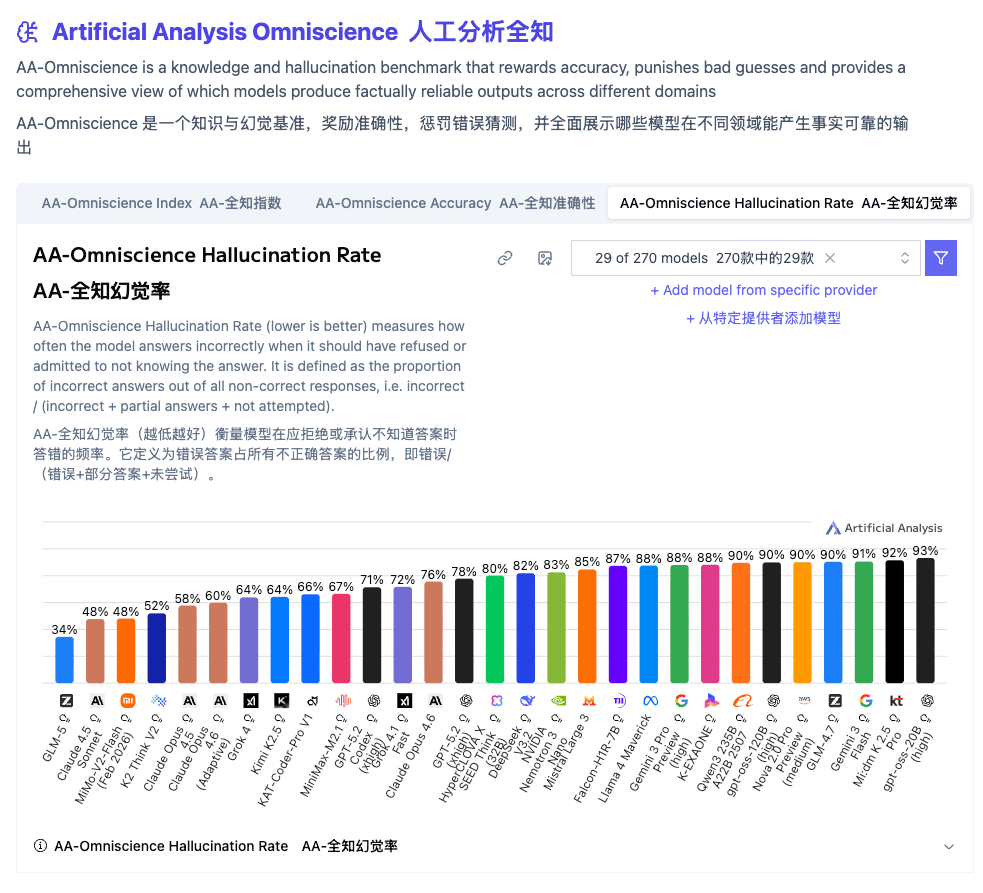
给孩子教的非常实诚了属于是。
既能干活,又不容易产生幻觉。。。GLM-5 的这波更新,属于完全冲着要让 AI 好好干活去整的。
在官网上世超还看到一个非常惊艳的案例,他们直接让 GLM-5 复刻了一个我的世界。
我下过来体验了一下,发现整个游戏只需要依赖浏览器就能运行。
能跑能挖能叠方块,操作手感非常流畅。
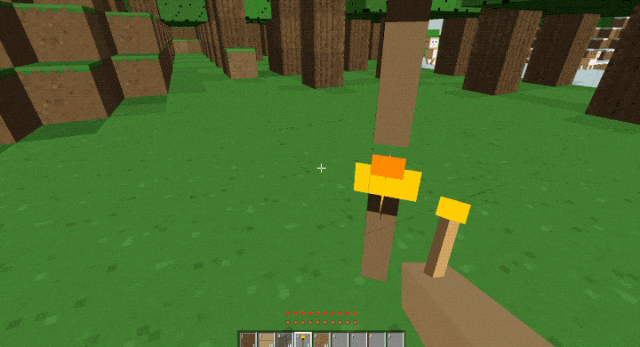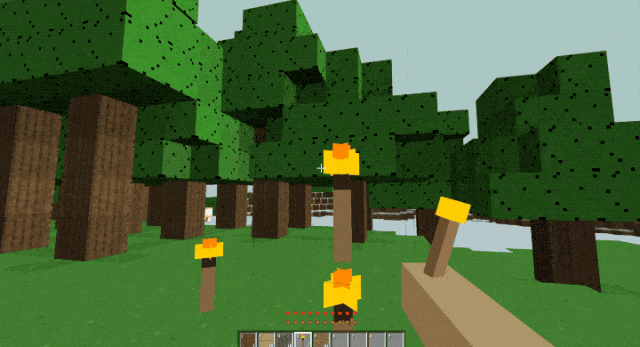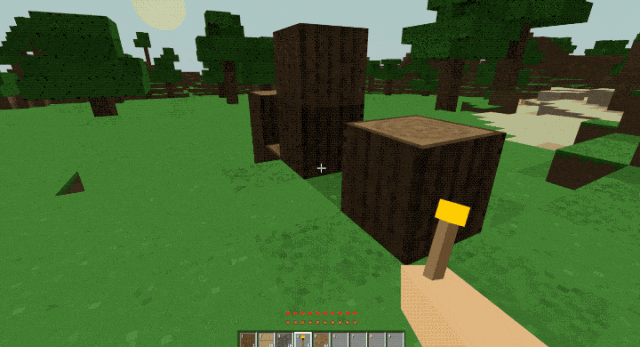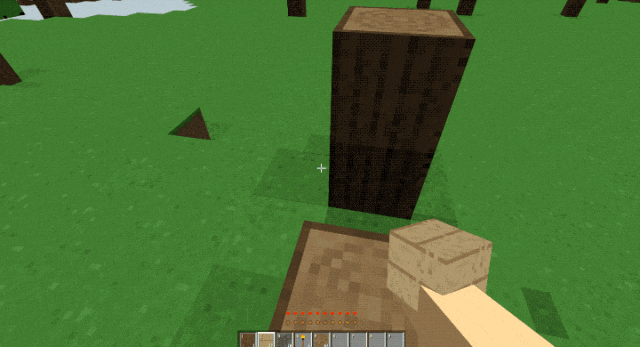
看别人拿 GLM-5 给整的这么猛,世超决定自己也简单试一试。
先来点简单点的活,拿前两天特别火的洗车问题来考考它。
我想洗车,我家距离洗车店只有 50 米,请问你推荐我走路去还是开车去呢?
别看这个问题简单,前几天整懵了一堆大模型,不管是 DeepSeek 还是 OpenAI,还是其他的大模型。。。都全军覆没

这些大模型都觉得 50 米的距离太近了,谁开车啊,于是转头建议大家走路去洗车。。。

而 GLM-5 面对这个问题,则是直接看透了问题的本质 —— 人不开车怎么洗车呢?然后完成了一波干净利索的输出。

当然,这种简单的逻辑题不翻车只能算合格,接下来,世超准备给它上点难度,看看它写代码的水平。
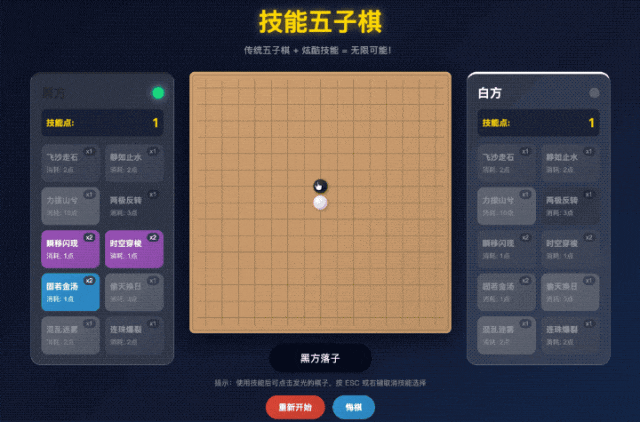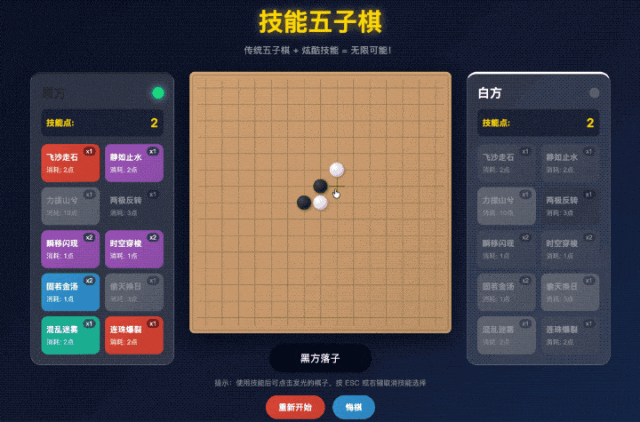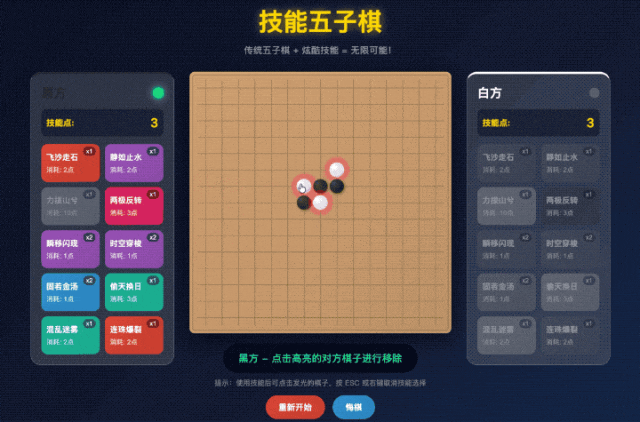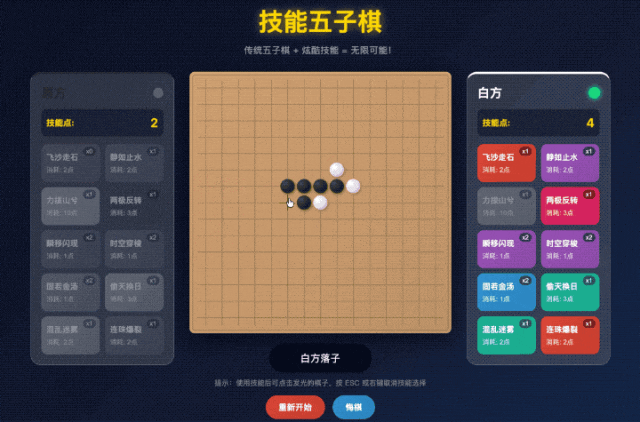
不知道差友们前段时间有没看过一个叫《技能五子棋》的喜剧。
剧里的演员们就在传统五子棋的基础上,加入了各种各样花里胡哨的技能元素。
比如,“飞沙走石” 这个技能,就是把棋盘上对方的一枚棋子给拿起来丢掉。

再比如“静如止水”这个技能,就是给对面玩家上定身术,让他不能继续下棋。
所以世超决定用 AI 来快速复刻一下这个整活游戏。
咱们就敲这么一段话,接下来全部交个 GLM 自由发挥。
结果不到三分钟,它就给我搓完了。
打开一看,整的还挺有模有样的。。。
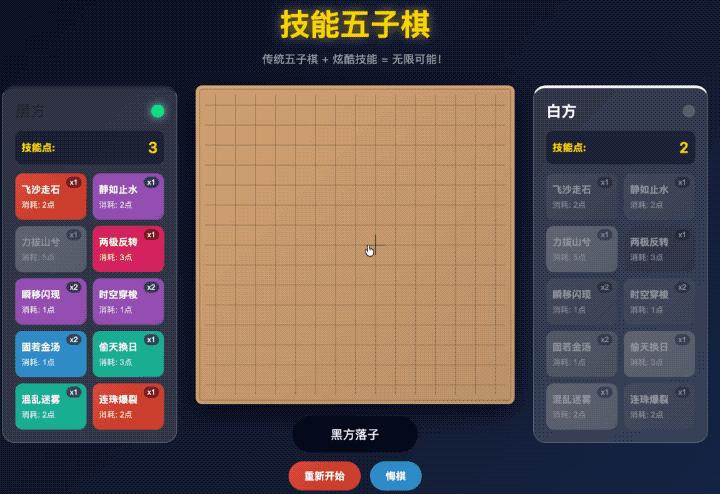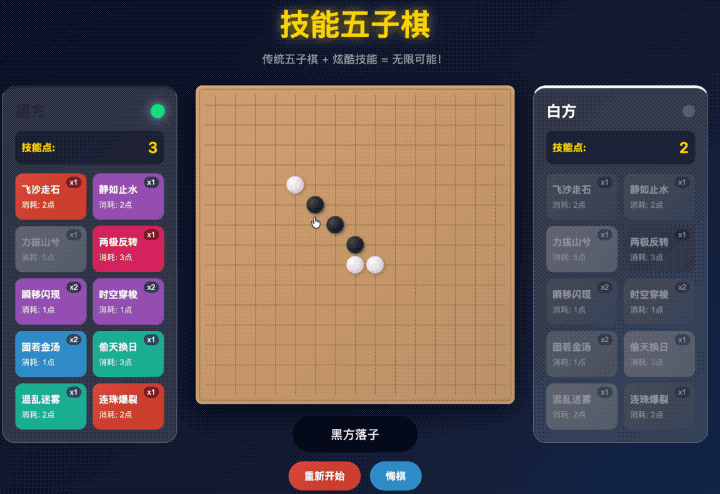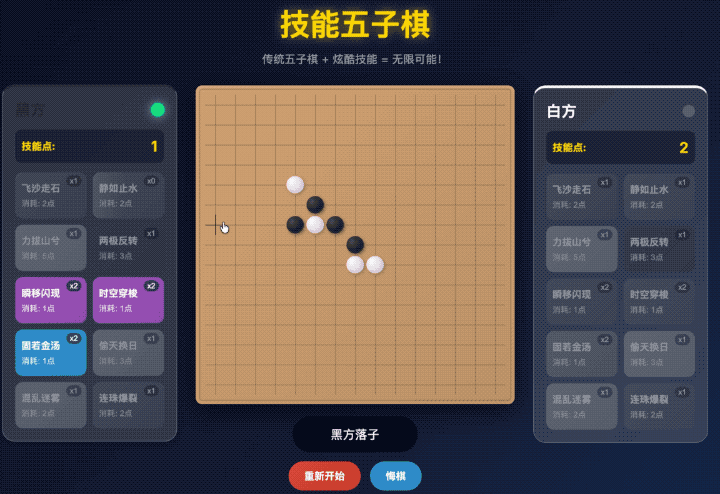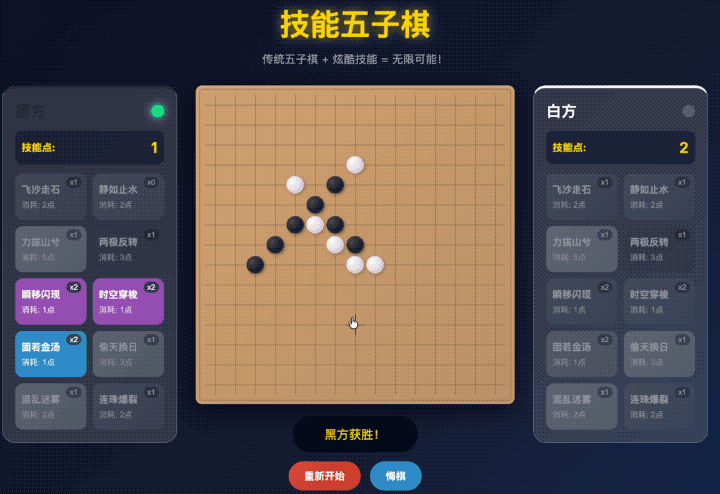
不但我要求它安排的四个技能都整上去了,还给自动生成了另外四个技能。
但是仔细一玩就露馅了。
点击了飞沙走石(移除对面一个棋子)的技能,把对面的棋子给扔掉了之后,
按理来说要么是我继续下棋,要么是对面下棋对吧。
这两种情况还在我的理解范围中,AI 给我写成哪种逻辑我都能理解。
但是 GLM 在这个 A or B 的选择题中,选了 or。
它让我选择给对面的棋子下到哪里,明显是神志不清逻辑错乱了。
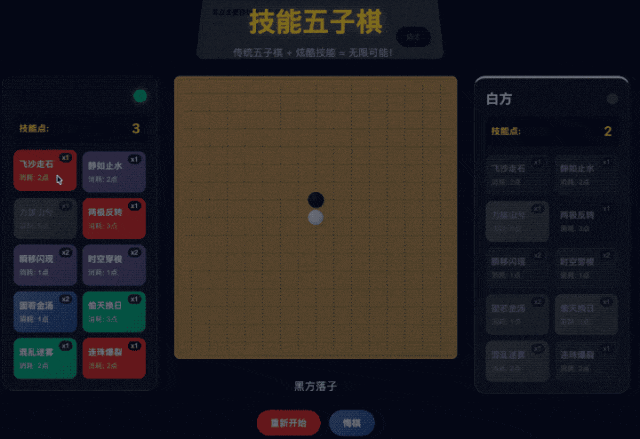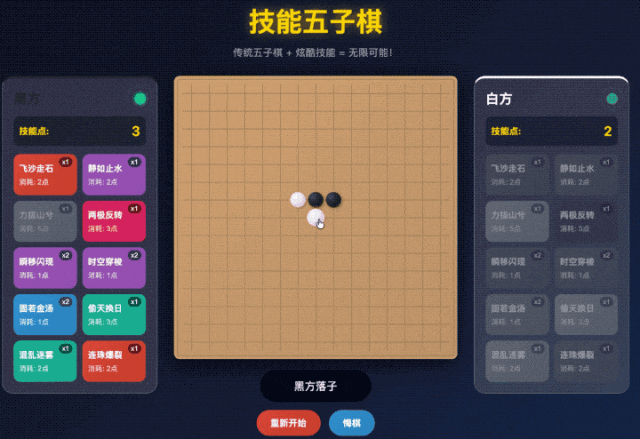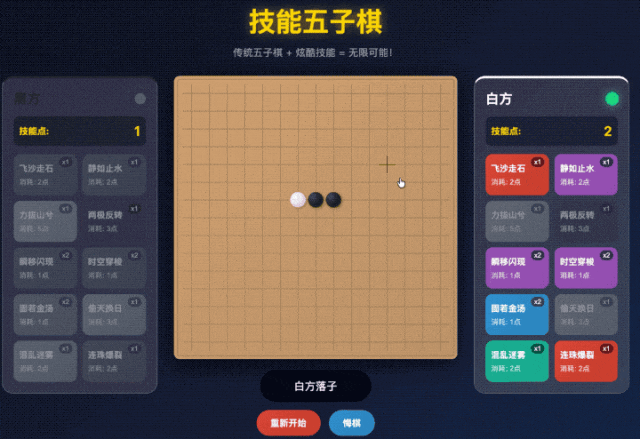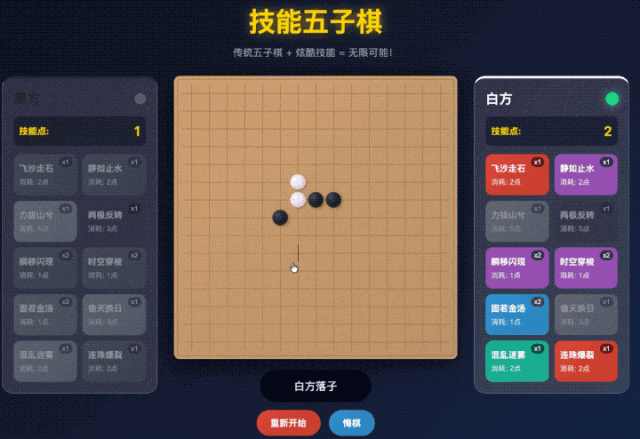
不过好在它也很听劝,把我们的需求再和它复述一下,那它很快就能 Get 到我们想要什么效果。
这样一来,我们就得到了一个可以和 AI 原地对战的技能五子棋游戏。
坦白说,现在 AI 写代码早就不是什么稀奇事了,能写出这种量级的 Demo 只能说是 GLM-5 的基本操作,还比较在世超的意料之中。
但 比较遗憾的是,因为这次上手的时间实在太短,世超没法拿那些真正复杂的业务代码去狠狠“拷打”一下它,看看它在那种成百上千个文件的大项目里,是不是还能保持这种清醒。
不过大家别急,今年世超手头正好攒了一堆复杂的烂摊子需求,准备年后面慢慢丢给它去跑一跑。
等后面深度体验了一段时间,真的摸清了它的上限和脾气,再来和大伙做个更详细的汇报。
撰文:早起
编辑:江江 & 面线
美编:素描
图片、资料来源:智谱官网、X、网络
[ 此帖被jjybzxw在2026-02-13 11:27重新编辑 ]

